Benker’s documentation 0.4¶
The Benker library can be used to convert tables from one format to another.
Yes, it only converts the tables, not the whole document, but it tries to do it well. The document itself is not changed, and the paragraphs inside the cells, neither. It’s your responsibility to do this part of the work.
Available formats¶
The Benker library works on XML documents. Currently, it can handle:
✱ OOXML is an XML-based format for office documents, including word processing
documents, spreadsheets, presentations, as well as charts, diagrams, shapes, and other graphical material.
This is the XML format used by Microsoft Word documents:
|
|
✱ CALS table model is a standard for representing tables in SGML/XML. Developed as part of the CALS Department of Defence initiative. The DTD of the CALS table model is available in the OASIS web site.
|
|
✱ Formex describes the format for the exchange of data between the Publication Office and its contractors. In particular, it defines the logical markup for documents which are published in the different series of the Official Journal of the European Union. Formex v4 is based on the international standard XML.
|
Conversion stages¶
To convert a document, Benker uses several stages:
Parse the source document and construct a nodes tree,
Search for table elements and construct the table objects,
Build the target nodes tree by replacing table nodes,
Serialise the target document.
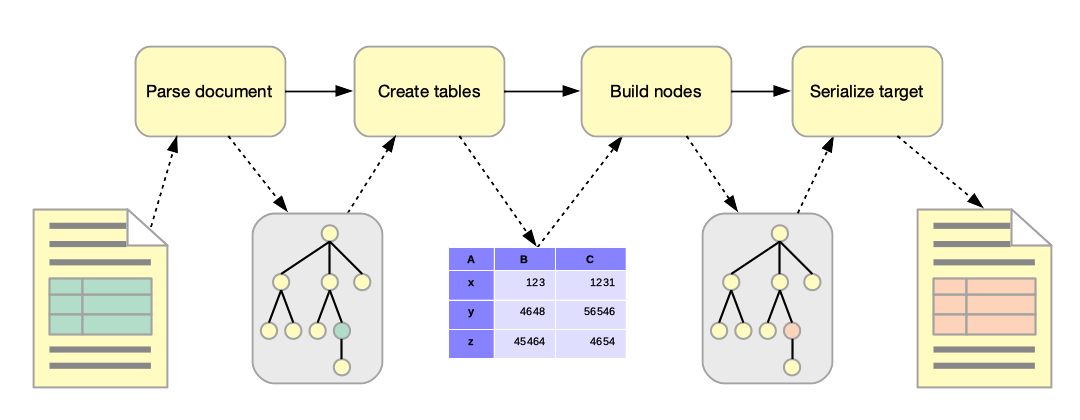
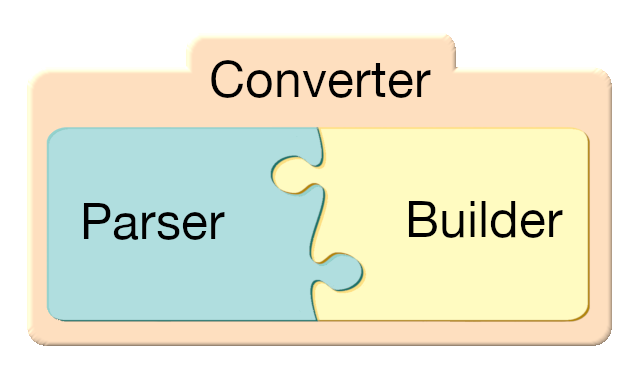
Converters: Parsers + Builders¶
The decoupling between parsing, building and final serialization allows a simplified and modular implementation. This decoupling also allows to multiply the combinations: it is easy to change a builder to another one, and to develop its own parser…
The advantage of this approach is that we avoid having a specific document conversion for each format pair (input, output). Instead, you can build a converter by choosing a parser and a builder, as you assemble the pieces of a puzzle.
The following table show you the available converters which groups parser and builders by pairs.
╲ |
|

|

|

|

|
– |
(unavailable) |
||

|
(unavailable) |
– |
(unavailable) |
(unavailable) |

|
(unavailable) |
(unavailable) |
– |
(unavailable) |

|
(unavailable) |
(unavailable) |
(unavailable) |
– |
You can create your own converter by inheriting the available base classes:
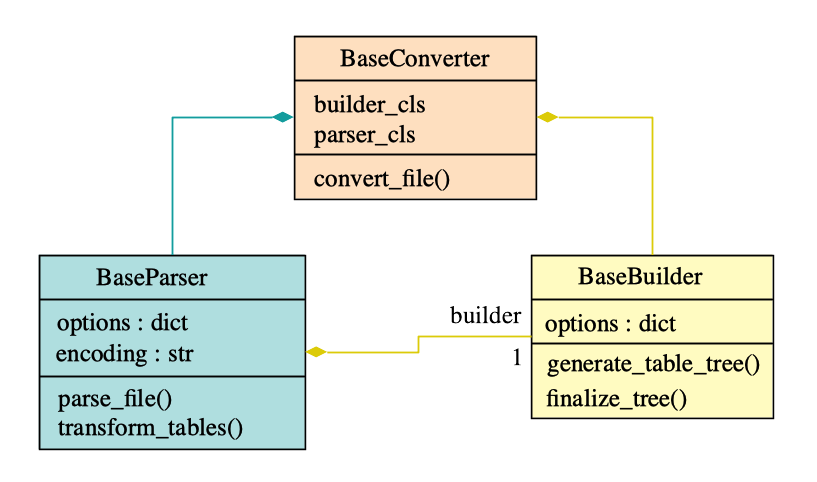
BaseConverter: inherit this class to create your own converter. Set your own parser class to the parser_cls class attribute, and your own builder class to the builder_cls class attribute.BaseParser: inherit this class to create your own parser. The methodtransform_tables()is an abstract method, so you need to implement it in your subclass: it must call the methodgenerate_table_tree()each time a table node is found and converted to aTableobject.BaseBuilder: inherit this class to create your own builder. The methodgenerate_table_tree()is an abstract method, so you need to implement it in your subclass: it must convert theTableobject into a target XML node (the resulting table format). You can also implement the methodfinalize_tree()to do any post-processing to the resulting XML tree.
Hint
Contribution is welcome!
Usage¶
For example, to convert the tables of a .docx document to Formex4 format, you can process as follow:
import os
import zipfile
from benker.converters.ooxml2formex4 import convert_ooxml2formex4
# - Unzip the ``.docx`` in a temporary directory
src_zip = "/path/to/demo.docx"
tmp_dir = "/path/to/tmp/dir/"
with zipfile.ZipFile(src_zip) as zf:
zf.extractall(tmp_dir)
# - Source paths
src_xml = os.path.join(tmp_dir, "word/document.xml")
styles_xml = os.path.join(tmp_dir, "word/styles.xml")
# - Destination path
dst_xml = "/path/to/demo.xml"
# - Create some options and convert tables
options = {
'encoding': 'utf-8',
'styles_path': styles_xml,
}
convert_ooxml2formex4(src_xml, dst_xml, **options)
This code produces a table like that:
<TBL COLS="7" NO.SEQ="0001">
<CORPUS>
<ROW>
<CELL COL="1" ROWSPAN="2">
<w:p w:rsidR="00EF2ECA" w:rsidRDefault="00EF2ECA"><w:r><w:t>A</w:t></w:r></w:p>
</CELL>
<CELL COL="2" COLSPAN="2">
<w:p w:rsidR="00EF2ECA" w:rsidRDefault="00EF2ECA"><w:r><w:t>B</w:t></w:r></w:p>
</CELL>
<CELL COL="4">
<IE/>
</CELL>
<CELL COL="5">
<IE/>
</CELL>
<CELL COL="6">
<IE/>
</CELL>
<CELL COL="7">
<IE/>
</CELL>
</ROW>
<ROW>
...
</ROW>
</CORPUS>
</TBL>
The content of the cells still contains OOXML fragments. It’s your own responsibility to convert them to the target format.
Contents:
- Benker
- Tutorials
- API
- Cell Size
- Cell Coordinates
- Box
- Styled object
- Grid Cell
- Grid
- Table
- Available Parsers
- Base Parser
- Office Open XML parser
- lxml Iterators
- Available Builders
- Base Builder
- CALS Builder
- Formex4 Builder
- Available Converters
- Base Converter
- Office Open XML to CALS converter
- Office Open XML to Formex4 converter
- Alphabet
- Drawing
- Units
- Changelog